Apache Spark 2.0 | Java | Spark | Course

What is Apache Spark?
Apache Spark is a free and open-source unified analytics engine for processing huge amounts of data. Spark is a programming interface for clusters that has implicit data parallelism and fault tolerance. The Spark codebase was first developed at the University of California, Berkeley's AMPLab and eventually donated to the Apache Software Foundation, which has been maintaining it since. It's a multi-language engine for running data engineering, data science, and machine learning on single-node or clustered servers.
More about Spark
The resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines and maintained in a fault-tolerant manner, is the architectural foundation of Apache Spark. Following the Dataframe API, the Dataset API was published as an abstraction on top of the RDD. The RDD was the primary application programming interface (API) in Spark 1. x, but in Spark 2. x, the Dataset API is encouraged, despite the fact that the RDD API is not deprecated. The Dataset API is still based on RDD technology.
Spark facilitates the implementation of both iterative algorithms, which visit their data set multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications may be reduced by several orders of magnitude compared to Apache Hadoop MapReduce implementation. Among the class of iterative algorithms are the training algorithms for machine learning systems, which formed the initial impetus for developing Apache Spark.
A cluster manager and a distributed storage system are required for Apache Spark. Spark provides standalone (native Spark clusters for cluster management, where you can manually launch a cluster or utilize the launch scripts provided by the install package. These daemons can also be operated on a single computer for testing purposes), Hadoop YARN, Apache Mesos, or Kubernetes. Spark can connect with a variety of distributed storage systems, including Alluxio, Hadoop Distributed File System (HDFS), MapR File System (MapR-FS), Cassandra, OpenStack Swift, Amazon S3, Kudu, Lustre, or a custom solution. Spark also has a pseudo-distributed local mode, which is often only used for development or testing, and in which distributed storage is not necessary and the local file system can be utilized instead; in this case, Spark is operated on a single machine with one executor per CPU core.
Features of Apache Spark
Data in batches or in real-time
Combine batch and real-time data processing with your chosen programming language: Python, SQL, Scala, Java, or R. Execute rapid, distributed ANSI SQL queries for dashboarding and ad-hoc reporting using SQL analytics. It is faster than the majority of data warehouses.
Data science on a grand scale
Exploratory Data Analysis (EDA) can be performed on petabyte-scale data without the need for downsampling.
Machine learning
Train machine learning algorithms on a laptop, then scale to fault-tolerant clusters of thousands of machines using the same code.
Speed
Spark, which was built from the ground up for performance, can process enormous amounts of data 100 times quicker than Hadoop thanks to in-memory computing and other enhancements. When data is saved on disc, Spark is even faster, and it now holds the world record for large-scale on-disk sorting.
User-Friendliness
Spark features simple APIs for working with huge datasets. This features over 100 data transformation operators as well as standard data frame APIs for managing semi-structured data.
Higher-level libraries, including support for SQL queries, streaming data, machine learning, and graph processing, are included with a Unified Engine Spark. These standard libraries help developers work more efficiently and can be used to create complicated processes.
What is the purpose of Spark?
Spark can handle several petabytes of data at a time, and it does so by distributing it among thousands of cooperating real or virtual computers. It supports languages like Java, Python, R, and Scala and has a large set of developer libraries and APIs; its versatility makes it well-suited for a variety of use cases. Spark is frequently used with distributed data stores like HPE Ezmeral Data Fabric, Hadoop's HDFS, and Amazon's S3, as well as popular NoSQL databases like HPE Ezmeral Data Fabric, Apache HBase, Apache Cassandra, and MongoDB, and distributed messaging stores like HPE Ezmeral Data Fabric and Apache Kafka.
Some uses of Apache spark
Stream processing-Application developers are increasingly dealing with "streams" of data, ranging from log files to sensor data. This information comes in a steady stream, frequently from numerous sources at the same time. While it is possible to keep these data streams on disc and analyze them later, it is sometimes more practical or vital to evaluate and act on the data received. Financial transaction data streams, for example, can be analyzed in real-time to identify– and reject– possibly fraudulent transactions.
Machine learning-As the amount of data collected increases, machine learning approaches become more viable and accurate. Before applying the same solutions to new and unknown data, the software can be trained to recognize and respond to triggers within well-understood data sets. Spark is a strong choice for training machine learning algorithms because of its ability to store data in memory and conduct repeated queries quickly. Running broadly similar queries at scale dramatically reduces the time it takes to sift through a collection of potential solutions and select the most efficient algorithms.
Rather than running pre-defined queries to create static dashboards of sales, production line productivity, or stock prices, business analysts and data scientists want to explore their data by asking a question, viewing the results, and then either slightly altering the initial question or drilling deeper into the results. This interactive query process necessitates systems that can respond and adapt quickly, such as Spark.
Data integration-Data generated by various systems throughout a company is rarely clean or consistent enough to be merged easily for reporting or analysis. ETL operations are commonly used to extract data from several systems, clean and standardize it, and then load it into a separate system for analysis. Spark (and Hadoop) are becoming more popular for reducing the cost and time necessary for ETL.
How much an Apache Spark developer earns?
To stay and grow in your position, you should be able to learn and adapt to those changes swiftly. An entry-level Spark developer can expect to make anywhere from Rs 6,00,000 to Rs 10,00,000 per year, while an experienced developer can expect to earn anywhere from Rs 25,00,000 to Rs 40,00,000.
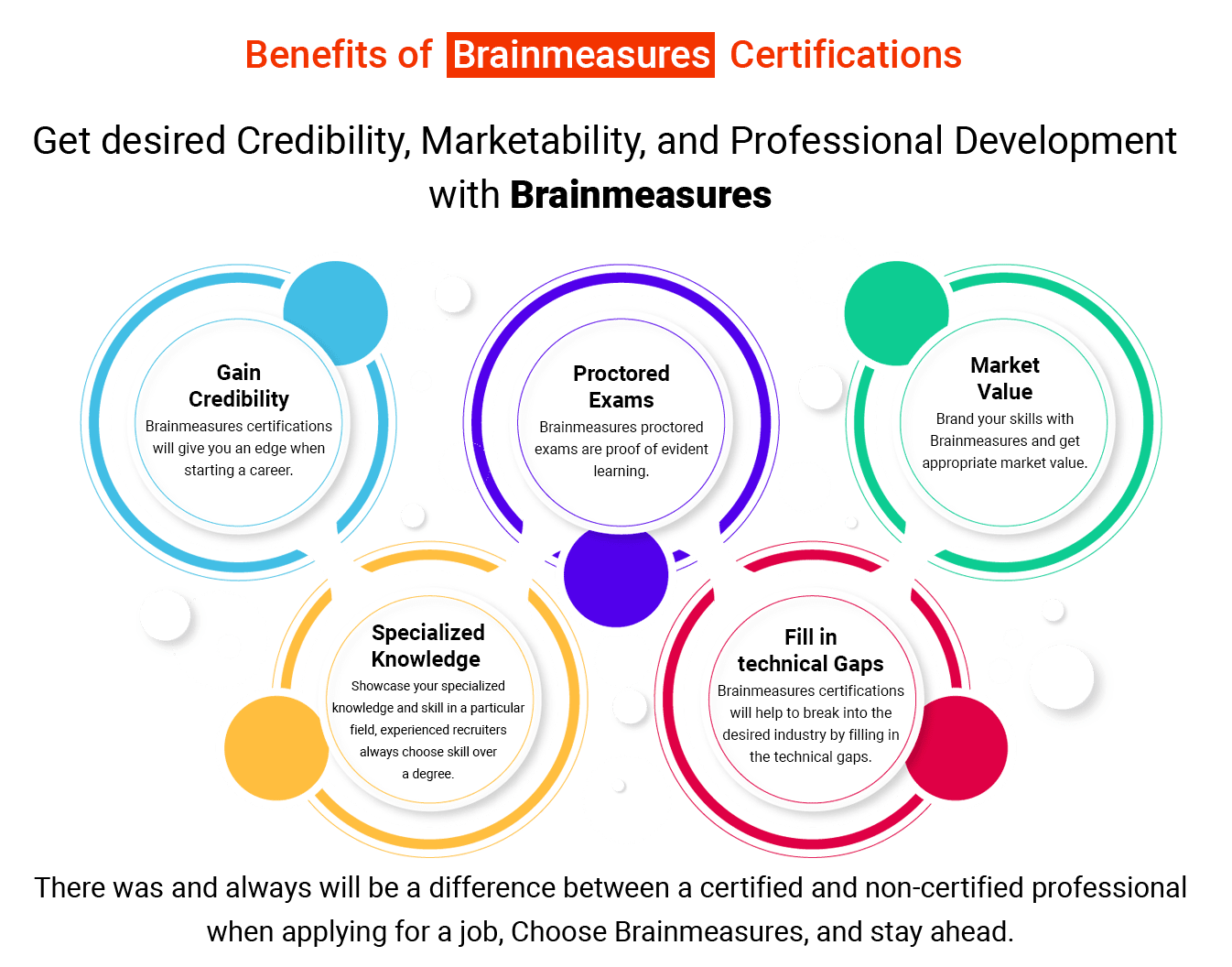
Why Brainmeasures?
Brainmeasures is an ISO-certified company that offers you high-end certification courses and many other services to boost your career. We hire experienced and qualified experts to create in-depth and prominent content courses to train our learners whether they are amateurs or have some experience in the field. We provide the best courses to offer you top-notch skills with a broad scope.
All of the services provided by Brainmeasures are offered at a very minimal and reasonable price. We also provide considerable discounts on various skills and courses to make them affordable for everyone.
At Brainmeasures, You will be provided with high-end courses after which you can get a hard copy certificate. You only have to clear a test and you will get a certificate which assures you a bright future by securing your job. Great companies in no time will hire you.
There are also many other facilities and features provided by Brainmeasures. To check these services click on the following links:
3000+ eBook Courses (Technical and Non-Technical)
2000+ Video Courses (Technical and Non-Technical)
Reviews (If you like our services let others know)
| Getting Started | 11 lectures | 17 mins |
| HTML and foundation | 11 lectures | 17 mins |
| Some title goes here | Preview | 01:42 |
| Welcome guide document | 10 Pages | |
| Some title goes here | 07:42 | |
| 2 Some title goes here | 07:42 | |
| Hello Some title goes here | 07:42 | |
| This is Some title goes here | 07:42 |
| CSS and foundation | 17 lectures | 87 mins |
| Some title goes here | Preview | 01:42 |
| Welcome guide document | 10 Pages | |
| Some title goes here | 07:42 | |
| 2 Some title goes here | 07:42 | |
| Hello Some title goes here | 07:42 | |
| This is Some title goes here | 07:42 |
| Making Responsive Website | 17 lectures | 87 mins |
| Some title goes here | Preview | 01:42 |
| Welcome guide document | 10 Pages | |
| Some title goes here | 07:42 | |
| 2 Some title goes here | 07:42 | |
| Hello Some title goes here | 07:42 | |
| This is Some title goes here | 07:42 |
| Learn Sass less Scss | 17 lectures | 87 mins |
| Some title goes here | Preview | 01:42 |
| Welcome guide document | 10 Pages | |
| Some title goes here | 07:42 | |
| 2 Some title goes here | 07:42 | |
| Hello Some title goes here | 07:42 | |
| This is Some title goes here | 07:42 |
| Learn about Cpanel and file uploads | 17 lectures | 87 mins |
| Some title goes here | Preview | 01:42 |
| Welcome guide document | 10 Pages | |
| Some title goes here | 07:42 | |
| 2 Some title goes here | 07:42 | |
| Hello Some title goes here | 07:42 | |
| This is Some title goes here | 07:42 |
Enroll in this course now and avail all the benefits.

Learn One-to-One Live Course - Coming Soon.



Brainmeasures certified Professionals work with global leaders.


The video online course is well-structured and comprehensive.
The topics are organized in proper sequence to enable the candidate understand them easily.
Easy to understand and implement in real life.
Sufficient pictures, tables, graphs have been provided to make this online Course more attractive to the readers.
Final certification exam conducted under surveillance of trained human proctor.
We will ship your hard copy anywhere you ask for.








1080039 Enrolled 04:52 Total Hours
$39
304080 Enrolled 20:38 Total Hours
$39
Take free practice test now
In today’s corporate world, a single wrong decision can cost you millions; so you cannot afford to ignore any indemnities you may incur from a single wrong hiring decision. Hiring mistakes include the cost of termination, replacement, time and productivity loss while new employees settle into their new job.
Our Mission is simply to help you attain Course Name knowledge which is at par with best, we want to help you understand Course Name tools so that you can use them when you have to carry a Course Name project and make Course Name simple and learnable.

Every month, more than 1,000 companies approach us to hire new employees, and we create customised tests (MCQs, Subjective type, one word, coding questions, Hackathon) for their drive. This proves employers' trust in our skill testing services, so having a Brainmeasures skill certificate on your resume will provide the edge you need.
We have followed up with every candidate of Brainmeasures who has taken a Brainmeasures Certificate for promotion or job and 97.78% confirmed that Brainmeasures Certificate helped them land their dream job.
Having a Brainmeasures certificate gives you an added advantage, skill is the biggest asset recruiters are looking for and what better way to prove that you are skilled than having a Brainmeasures certificate on your resume.
Brainmeasures exams are proctored which means candidates are monitored during the exam and this system has been designed to avoid any stance of cheating, while the candidate takes the test his video is recorded and the same can be provided to the employer or hiring manager if required and the certificate can be verified on-site using transcript number given on certificate.
Brainmeasures tests are developed by professionals with years of working experience which means only candidates with real skills pass the exam.
HR and Hiring Managers of leading organizations across the globe choose Brainmeasures certified professionals as we have proved in the last 13 years that when it comes to skill-testing no one does it better than Brainmeasures.
Brainmeasures.
Global leader in online certification and employment testing
info@brainmeasures.com Enquiry@brainmeasures.com